
Qué es un Model de Simulación?
La modelización por simulación es una técnica para encontrar soluciones a problemas del mundo real. En muchos casos, no podemos experimentar en el mundo real y, por lo tanto, nos gustaría crear un modelo de este sistema real y experimentar con el modelo. Este modelo computacional representa un "mundo sin riesgos". El modelo siempre será menos complejo que el mundo real, ya que dejaremos fuera los detalles que consideramos innecesarios para el efecto que queremos estudiar. Sin embargo, la capacidad de probar soluciones en un mundo sin riesgos no es la única razón por la que creamos modelos de simulación. Los problemas del mundo real son complejos y, a menudo, no hay otra forma de resolver el problema. La simulación puede modelar sistemas complejos y, al jugar con este sistema, podemos ver la trayectoria de los estados del sistema a lo largo del tiempo. De esta manera, podemos desarrollar una mejor intuición de las relaciones de causa y efecto y alcanzar la solución óptima.
Aprendizaje Reforzado
El aprendizaje por refuerzo es una técnica de aprendizaje automático en la que el agente de aprendizaje aprende qué acciones tomar para maximizar una señal numérica de recompensa.
Se basa en la idea de plantear los problemas como un proceso de decisión de Markov, donde un agente de Inteligencia Artificial (un algoritmo especializado) aprende una política de control para siempre elegir la mejor acción posible para un estado dado del sistema. Idealmente, este sistema es algo aleatorio y dinámico, lo que hace que un enfoque de aprendizaje basado en recompensas sea superior en comparación con otras teorías de control tradicionales. La aplicación exitosa de redes neuronales en conjunto con el aprendizaje por refuerzo (de ahí el nombre "Deep Reinforcement Learning" o Aprendizaje Profundo por Refuerzo) abrió nuevos horizontes para lidiar con escenarios más complejos que antes se consideraban imposibles. El aprendizaje profundo por refuerzo (DRL) sigue este método, utilizando una red neuronal profunda para representar la política.
La simulación como entorno de entrenamiento para el Aprendizaje por Refuerzo
El Aprendizaje por Refuerzo (RL) requiere una gran cantidad de episodios o interacciones de "prueba y error" con los entornos para aprender una buena política. Por lo tanto, se necesitan simuladores para lograr resultados de manera oportuna y rentable. El modelo de simulación se convierte esencialmente en el entorno en el que el agente de RL aprenderá.
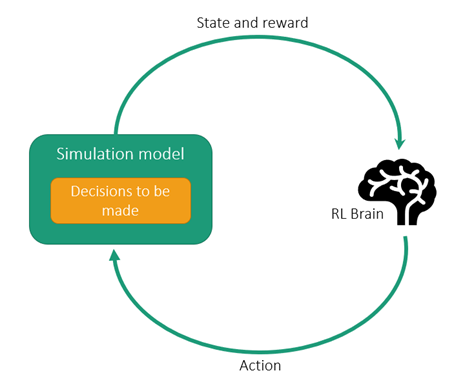
Dado que el modelo de RL aprende mediante un proceso continuo de recibir recompensas por cada acción tomada, puede aprender a responder a entornos imprevistos. Los sistemas industriales, incluida la gestión de la cadena de suministro y los procesos industriales, son buenos ejemplos de problemas grandes y complejos que son perfectamente adecuados para ser resueltos con el aprendizaje por refuerzo.
En el caso de la gestión de la cadena de suministro, sería extremadamente difícil, si no imposible, escribir un programa que pudiera gestionar eficazmente todas las posibles combinaciones de circunstancias que ocurren en los escenarios cotidianos. Los camiones podrían averiarse, los alimentos podrían estropearse, el mal tiempo podría obligar al cierre de carreteras, la lista de situaciones potenciales es prácticamente infinita. Como resultado, el sistema debe ser altamente adaptable. Una vez más, aquí es donde las técnicas de aprendizaje por refuerzo son especialmente útiles, ya que no requieren una gran cantidad de conocimiento o datos previos para proporcionar recomendaciones y soluciones útiles.
Algunas situaciones en las que se recomienda un enfoque basado en simulación y RL son:
- Requisitos de extrema robustez: Un sistema de control existente o un motor de optimización requiere múltiples configuraciones diferentes para funcionar correctamente en todas las condiciones.
- Múltiples objetivos de optimización o cambios en los objetivos: Un sistema de control existente tiene dificultades para optimizar eficientemente hacia múltiples objetivos ó si los objetivos de optimización cambian según las condiciones ambientales.
- Sobrecarga del operador: Los operadores no pueden procesar muchas variables en tiempo real mientras controlan los sistemas, o los ingenieros necesitan ayuda para tomar decisiones en diversos escenarios.
- Tareas en las que una persona puede superar cualquier método de optimización tradicional: Dichas tareas podrían volverse autónomas utilizando un enfoque basado en RL.
Si crees que tú y tu organización podrían beneficiarse del aprendizaje por refuerzo impulsado por la simulación, contáctanos para saber por dónde empezar.



